How we handle forks
In the Crypto Ecosystems data below, we can see that project teams list all of the repos that are used in their work, as well as the repos that are used in sub projects of their project.
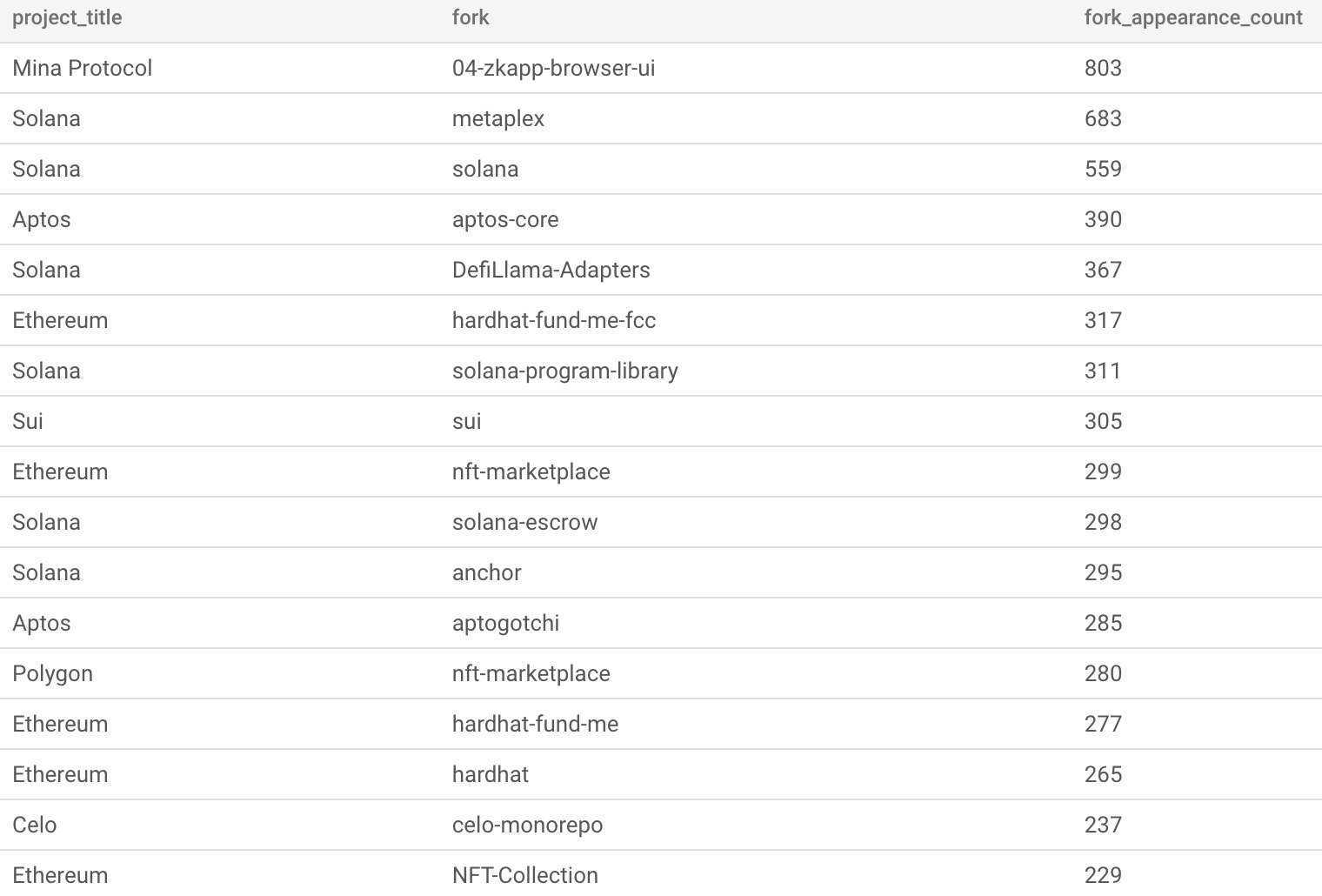
We also see that some repos are widely used across the crypto ecosystem, and that some are forks of other repos.
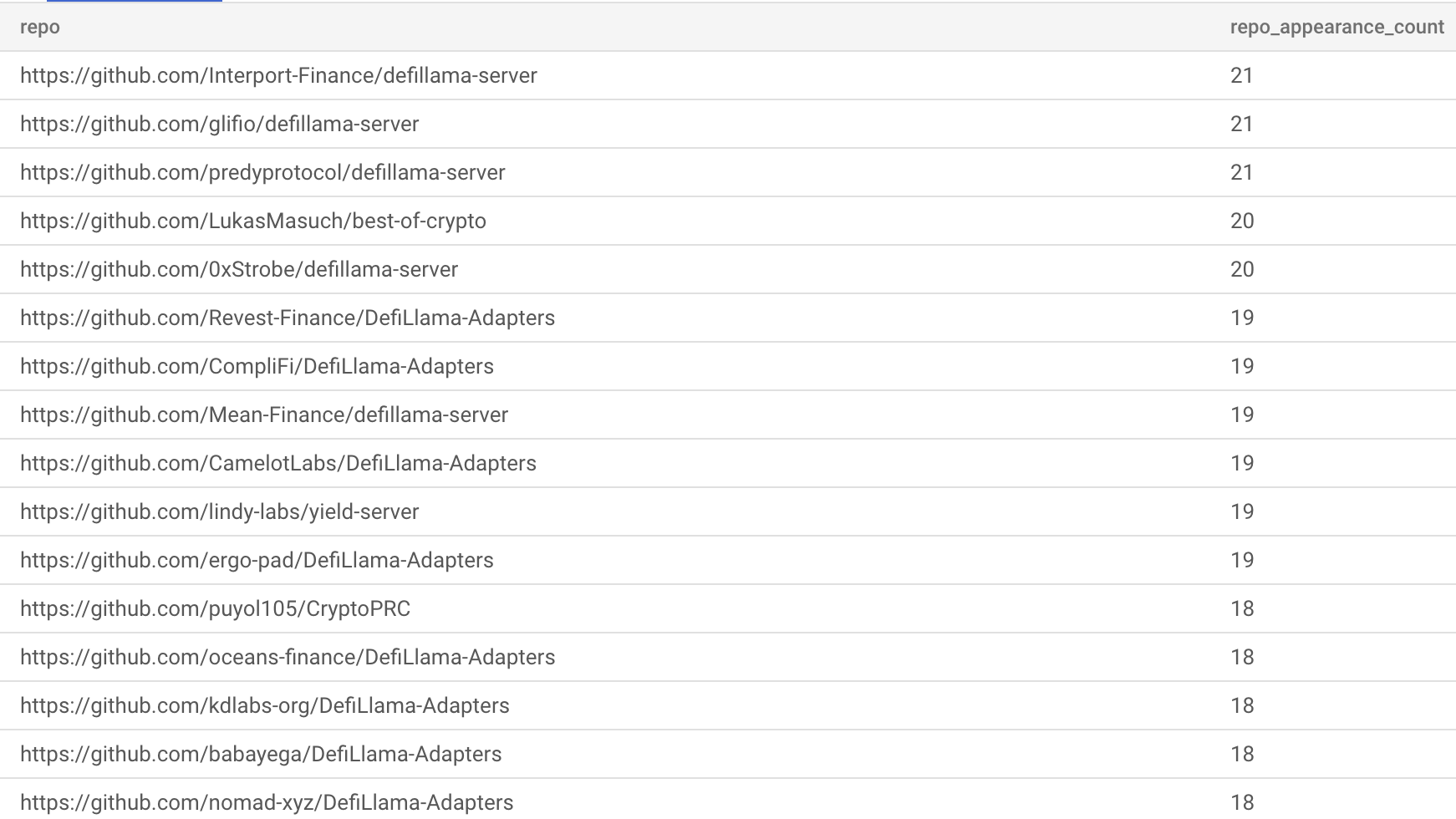
For repos that are widely forked across the ecosystem, we run the risk of double counting metadata when we aggregate by top level project. Examples of metadata that are aggregated include stargaze, forks, commits, watchers, and contributors. The double counting problem is only a problem for metrics that are retained in the forked repo i.e., commit count and contributor list. Stargaze, forks, and watcher counts are reset to zero in forks.
What is the best way to handle aggregated repo metadata at the project level? We could go upstream and only aggegrate metadata to the parent repo, but this would discard any work performed by the forked repo. In many cases, we simply aggregate the repo metadata regardless of fork status. The downside is that forked repo metadata will be aggregated to a project, even if that fork has not deviated from the parent repo.