Repo attributes
We use machine learning models to generate development attributes that can be used to better filter, sort, and search the information on the builder.love data platform. For instance, we have labeled all developer tooling repos so that these can be easily searched for within a project repo list.
Training data set
The population of development repositories is filtered to remove archived repos, repos without code, repos with only markdown code, and repos without a description or a readme. These repos represent a development sandbox environment and not code that is meant to be used for meaningful use cases. These repos are much less important in our assessment of the legitimacy of projects and contributors.
Classification implementation
We are currently using one feature table for all classification models.
The feature dataset is created by searching for a set of keywords within the repo description, as well as the following files (if found): readme file, package.json, pyproject.toml, pom.xml, build.gradel, build.gradle.kts, go.mod, Cargo.toml, etc.
The keyword search generates boolean fields.
We use the boolean fields and other information from the database to train a classification model that can predict if a repo is educational in nature, code scaffolding, developer tooling, infrastructure, or an end-user application. All models achieved accuracy scores above 75. This means 75% of the classifications made by the models were correct—either true positive or negative.
We think a false positive i.e., predicting a repo is a developer tooling codebase when it is not, is more costly at this stage than a false negative i.e., failing to classify a developer tooling codebase. For this reason we have increased the classification confidence threshold when model predictions were not precise enough.
In their current state, the models are useful. But they do not perform as well as we would like. We know the real work to improving them is better labeling in our training data—this takes time and a well-thought through framework for making decisions on the margins.
Further work is needed to explore ways to reduce the need for data labeling. N-shot learning models are designed specifically for this, and will be researched for cost/feasability.
Education classification
This class of repos exists solely for the purpose of learning and communicating ideas and facts. These repos can be identified using keywords:
- demo
- hackathon
- tutorial
- ‘example’/’examples’ in the repo name
- awesome/awesome collection
- documentation/documents/documentation site
- ‘sample’ in the repo name
- whitepaper
- bootcamp
- interview
- lesson
- quickstart
- educate
- guide
- ‘hello-world’ in repo name
- workshop
- ‘collection of learnings’
- ‘learn solidity’
- ‘starter project’
The classification model is here
Performance:
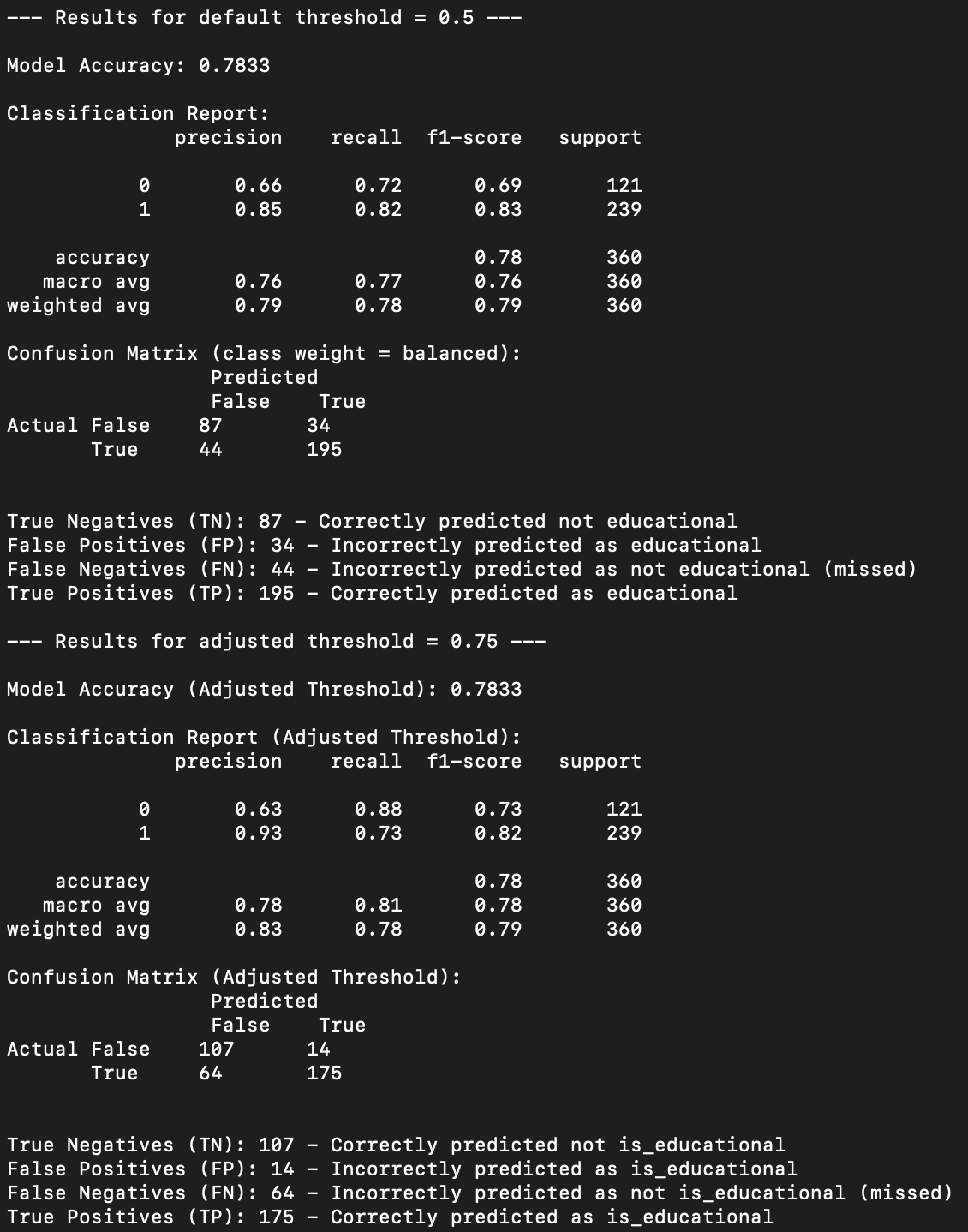
From the below, we can see that the model is correctly predicting a repo is for educational purposes 87 percent of the time using the default confidence threshold of 50 percent. However, given our conservative approach we only want to label a repo when we have high confidence, we increase the confidence threshold to 75 percent and rerun the predictions. Using this parameter the model is correctly predicting the repo is for educational purposes 93 percent of the time. This is an acceptable result. Applying the more conservative model to the population of repos results in 66,998 (out of 314,747) repos classified as educational.
Scaffold classification
Repos with code that automatically generates the basic, repeatable steps required to implement technology.
keywords:
- scaffold
- template
- boilerplate
The classification model is here
performance:
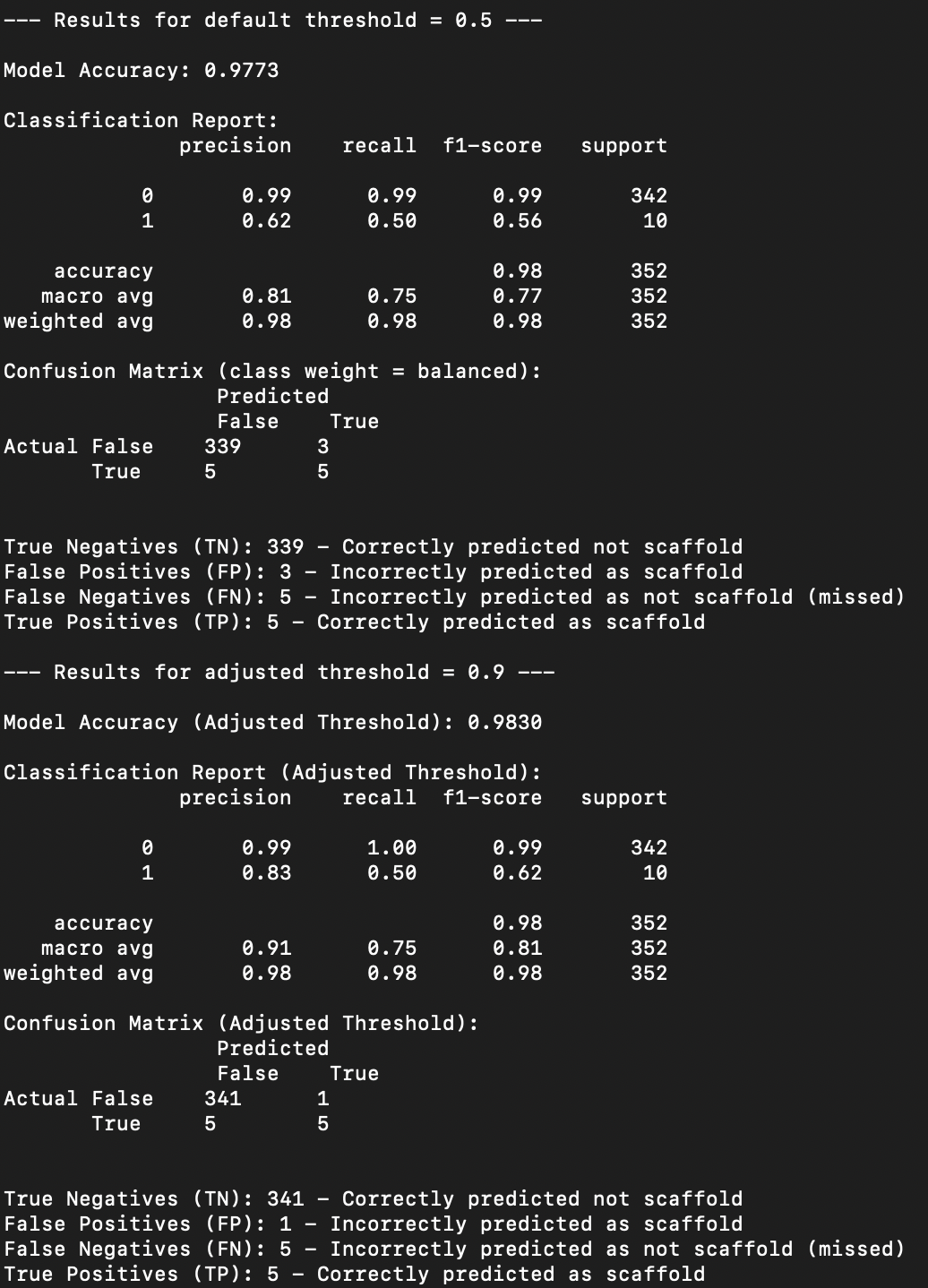
This model is correctly predicting a repo is scaffolding only 62 percent of the time using the default confidence threshold of 50 percent. The model is also only covering 50 percent of all scaffold repos in the test set. The model is not good at predicting scaffolding, it would seem. But, given the extreme imbalance in the test data labels, it makes sense that it is imprecise. Recall, or the coverage of scaffold repos, is concerning. For this model we adjust the confidence threshold upwards, but this time we adjust up significantly to 90 percent confidence threshold. Using this parameter the model is correctly predicting the repo is scaffolding 83 percent of the time. The model’s ability to catch all scaffold repos didn’t change. This model is fairly poor, but we implement it with the high confidence thresholds in order to appropriately label scaffold repos that we are certain about. Applying the model to the population of repos results in only 4,968 (out of 314,747) repos classified as scaffolding.
Developer tooling classification
Developer tooling repos extend functionality. Our basic framework for making decisions about whether or not a repo is developer tooling is as follows:
Pattern:
Is this repository a tool, library, framework, or utility that a developer would use to build, test, analyze, or deploy software more effectively in a general sense, or for a broad category of tasks?
Anti-pattern:
Is the primary purpose of this repository to demonstrate how to use another specific tool, SDK, or product, or to provide an example application for it?
key words:
- A plug in
- an SDK
- CLI
- test suite
- tool/tools/toolkit
- framework
- has a package.json, pyproject.toml, Cargo.toml, or other package manager file
- If a package manager file exists, the ‘name’ field value can be searched via npm, PyPi, or other code distribution API to verify it is a distributable library. This is not implemented yet.
The classification model is here
Performance:
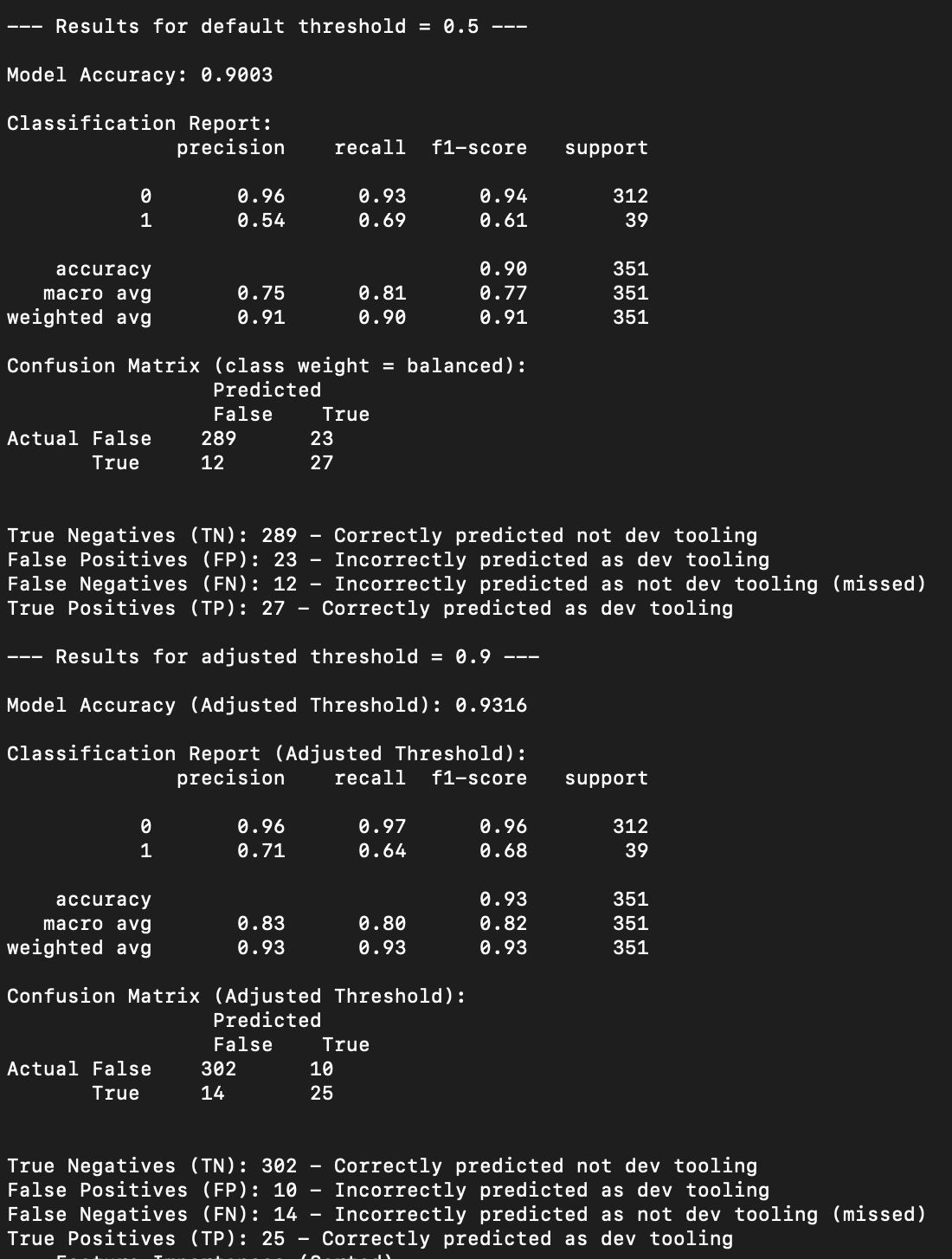
Similar to the scaffolding model, this model has low precision when predicting a repo is dev tooling at 54 percent, and low coverage with catching only 69 percent of all dev tooling repos. If we bump the confidence threshold up to 90 percent, the model is much more precise at 71 percent, but catching less of the dev tooling repos with a 64 percent recall. This model is not performing well. But, we use a conservative confidence level in order to only apply the dev tooling label when we are fairly confident the repo is dev tooling. When applied to the population this model labeled 40,285 (out of 314,747) repos as dev tooling.
Infrastructure classification
In the blockchain context, infrastructure refers to the foundational components that enable the deployment, operation, and interaction with blockchain networks and smart contracts. This includes low-level services, data layers, communication protocols, and core network components that are not directly user-facing applications but support their functionality.
Pattern:
- A smart contract codebase that is used to enable verifiable functionality, where the execution environment is a blockchain.
- A service or network component that exposes data, or makes information sharing between machines easier and standardized.
Anti-pattern:
- Educational content
- Scaffolding
- Specific use cases
- End users are customers
key words:
- protobuf (without front end code)
- bindings (without front end code)
- smart contract libraries, like hardhat, anchor (without front end code)
- package.json has backend dependencies, like express, fastify, nest, etc.
- dominant language is Solidity, Move, Rust, Vyper, Cairo, Go, etc
The classification model is here
Performance:
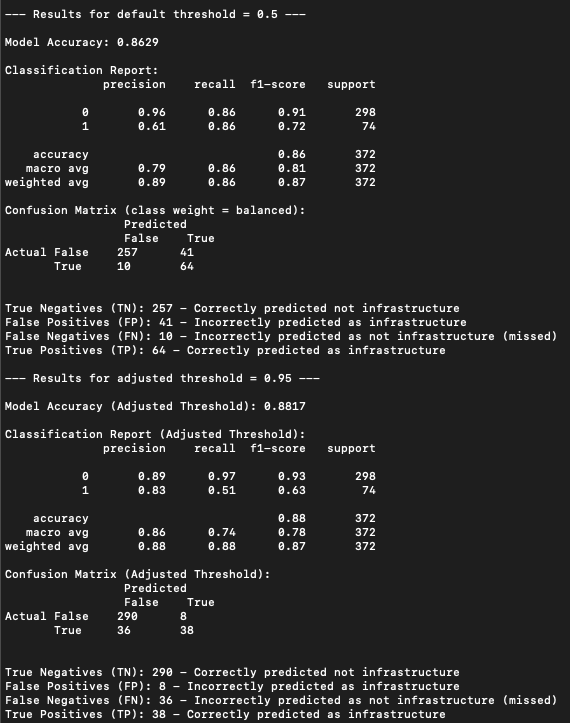
The infrastructure model was very poor when we first ran it. The model was precise in its positive predictions less than 20 percent of the time. We spent a lot of time labeling, and got the precision up into the 80 percent range. Applying the model to the population yields 38,263 repos classified as infrastructure.
End-user application classification
An application has a User Interface (UI) i.e., the repository contains the code for a website, a mobile app, or a desktop program. Its primary concern is how to present information to the user and how to handle their input.
The application is built for end-users. The repository's documentation will focus on how to run the app, not necessarily how to build new things with its components. The code connects to Infrastructure i.e., an application is a consumer of infrastructure.
key words:
- package.json has UI frameworks and libraries referenced, like vue, react, etc, and css styling libraries.
- dominant language is Javascript, Typescript, css, vue, etc.
The classification model is here
Performance:
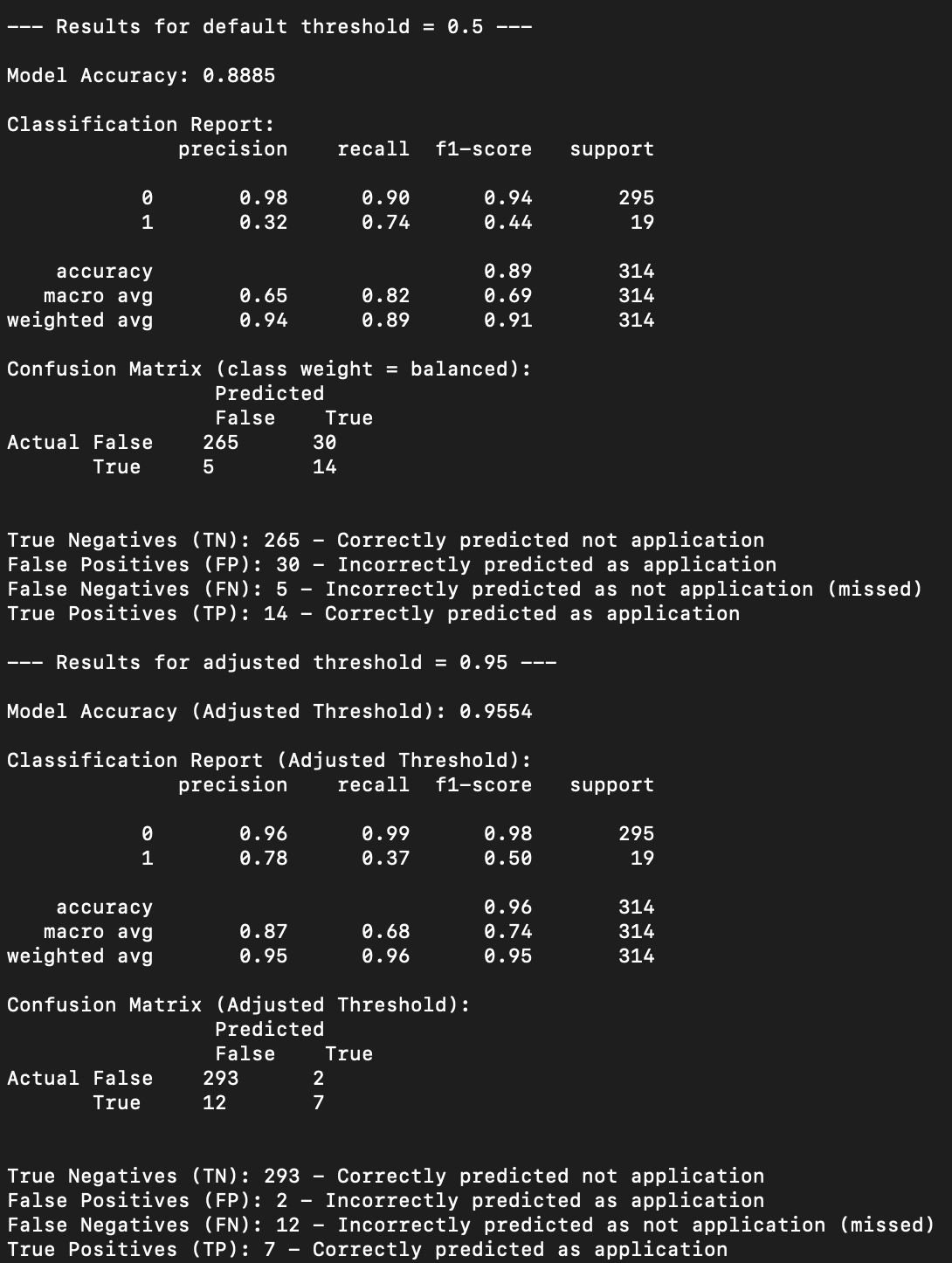
From the below we can see this model is not doing a great job of predicting repos as applications, with a “shot on goal” ratio of 32 percent, and catching 74 percent of repos that consist of application code. This model, like the scaffold and dev tooling models, suffer from an imbalanced training data set i.e., there are many more false values than true values. This makes the model really good at predicting when a repo is not application. So here too we bump up the confidence threshold, this time to 95 percent, and sacrifice recall so that we can improve precision. The outcome is we will fail to label repos as application when they are, but when we do label as application we are very confident in the label. When we apply this model to the population we positively label 26,568 (out of 314,747) repos as application.
Pipeline architecture
You can see the labelled data here
There are two challenges with the pipeline design:
- The features should be updated on some schedule; do we retrain the model when this happens? If so, then we need a process to ensure labels in the training set are also updated. Manually reviewing thousands of labels is tedious work
- Let’s say we update the features and rerun the models on a monthly cadence; how do we ensure there are not wholesale changes to the predictions such that the user experience is poor?